I've tested POPFile accuracy with [xmltraintest.py] using 22,340 e-mails for 17 buckets.
POPFile is using Kakasi as the Japanese 'wakati-gaki' parser now. If we use MeCab, does the accuracy change? And when using the simple parser (split word by character kind) ?
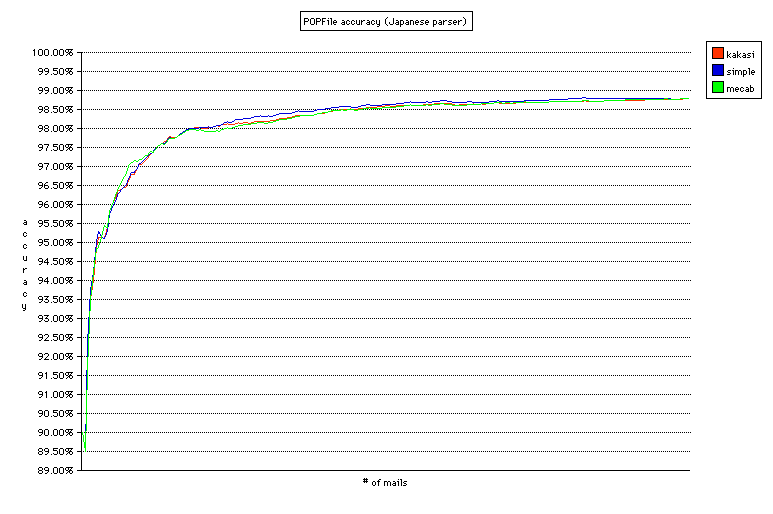
事前の予想では、MeCab>Kakasi>simple(文字種に寄る分割)となると予想していたのだが、結果は分かち書きのプログラムにかかわらずほぼ同じ精度であった。グラフがほとんど重なってしまっていて見にくいが、それぞれの精度は Kakasi 98.791%(分類ミス 214/unclassified 56)、simple 98.791%(分類ミス 211/unclassified 59)、MeCab 99.796%(分類ミス 214/unclassified 55)と、少数第 2 位まで同じ結果(Kakasi と simple はまったく同じ)。22,340 通を分類して 1 通しか変わらないのだから、これはもう「同じ」と言って差し支えないだろう。意外だったのは simple が大変健闘したこと。文字種による分割だけでこれだけの精度が出るというのはおもしろい。中盤(?)では simple が最も精度がよい部分もあり、メールの内容によっては有利な場合もありそうだ。
辞書や外部モジュールが不要であること、速度面で有利なことを考えると、文字種のみの分割を選ぶことができるように機能追加を行いたいところ。
コーパスの大きさ(vacuum コマンドで最適化したデータベースのサイズ)は Kakasi が最も小さく 4,653,056 バイト、次いで simple が 4,973,568 バイト、MeCab が 5,074,944 バイト。Kakasi が若干小さいが、それほどの差は見られない。
グラフを見ると、(Kakasi を使った場合)2,800 通(70 通のメールを再分類)あたりから安定して 97.5% 以上の精度が出るようになっている。90% は最初の 300 通(24 通を再分類)で達成、95% は 700 通(34 通を再分類)で達成している。受信するメールの数にもよるが、バケツの数が多くても非常に短期間で高い精度を達成することができる。
See also(the log of xmltraintest.py):
![[Home]](./images/amatubu.png)