I've tested POPFile accuracy with [xmltraintest.py] using 22,340 e-mails in 17 buckets.
POPFile is using Kakasi as the Japanese 'wakati-gaki' parser now. If we use MeCab, does the accuracy change? And when using the simple parser (splitting words by character kind) ?
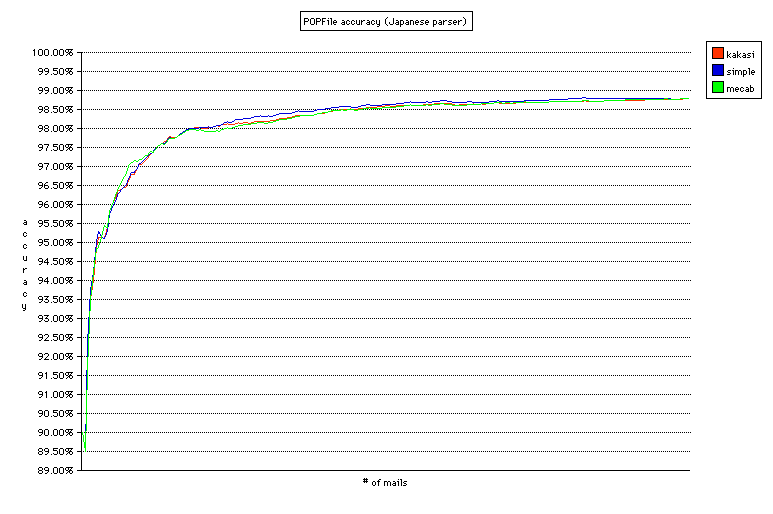
I thought MeCab is the most accurate and the simple parser is the least, because MeCab has the large dictionary and it is most accurate in parsing Japanese text. But the above result says that MeCab and the simple parser is as accurate as Kakasi.
Kakasi has 98.791% accuracy (214 classification erros and 56 unclassifieds), MeCab has 98.796% (214 classification errors and 55 unclassifieds) and the simple parser has 98.796% (211 classification erros and 59 unclassifieds). MeCab is more little bit accurate than the others, but the difference is only one e-mail out of 22,340 e-mails.
Since the simple parser does not require any external modules, I want to create a new option to use it as Japanese parser in the next version of POPFile.
See also(the log of xmltraintest.py):
![[Home]](./images/amatubu.png)