|
事前の予想では、MeCab>Kakasi>simple(文字種に寄る分割)となると予想していたのだが、結果は分かち書きのプログラムにかかわらずほぼ同じ精度であった。グラフがほとんど重なってしまっていて見にくいが、それぞれの精度は Kakasi 98.791%(分類ミス 214/unclassified 56)、simple 98.791%(分類ミス 211/unclassified 59)、MeCab 99.796%(分類ミス 214/unclassified 55)と、少数第 2 位まで同じ結果(Kakasi と simple はまったく同じ)。22,340 通を分類して 1 通しか変わらないのだから、これはもう「同じ」と言って差し支えないだろう。意外だったのは simple が大変健闘したこと。文字種による分割だけでこれだけの精度が出るというのはおもしろい。中盤(?)では simple が最も精度がよい部分もあり、メールの内容によっては有利な場合もありそうだ。 |
|
事前の予想では、MeCab>Kakasi>simple(文字種に寄る分割)となると予想していたのだが、結果は分かち書きのプログラムにかかわらずほぼ同じ精度であった。グラフがほとんど重なってしまっていて見にくいが、それぞれの精度は Kakasi 98.791%(分類ミス 214/unclassified 56)、simple 98.791%(分類ミス 211/unclassified 59)、MeCab 98.796%(分類ミス 214/unclassified 55)と、少数第 2 位まで同じ結果(Kakasi と simple はまったく同じ)。22,340 通を分類して 1 通しか変わらないのだから、これはもう「同じ」と言って差し支えないだろう。意外だったのは simple が大変健闘したこと。文字種による分割だけでこれだけの精度が出るというのはおもしろい。中盤(?)では simple が最も精度がよい部分もあり、メールの内容によっては有利な場合もありそうだ。 |
[xmltraintest.py] を POPFile 0.22.4 のアーカイブに対応するように修正したものを使い、私の環境でアーカイブされたメール 22,340 通を元に精度の比較を行った。17 のバケツに分類された 22,340 通のメールを順に分類させ、分類が誤っていれば学習させていくという流れ。バケツの数が 17 と多いため、単純に spam と非 spam とに分類するよりも精度面では不利なテストかもしれない。
現在の POPFile では分かち書きに Kakasi を利用しているが、これを MeCab に変更した場合、精度に違いはあるのかどうか。また、より単純な文字種のみによる分割の場合はどうか。
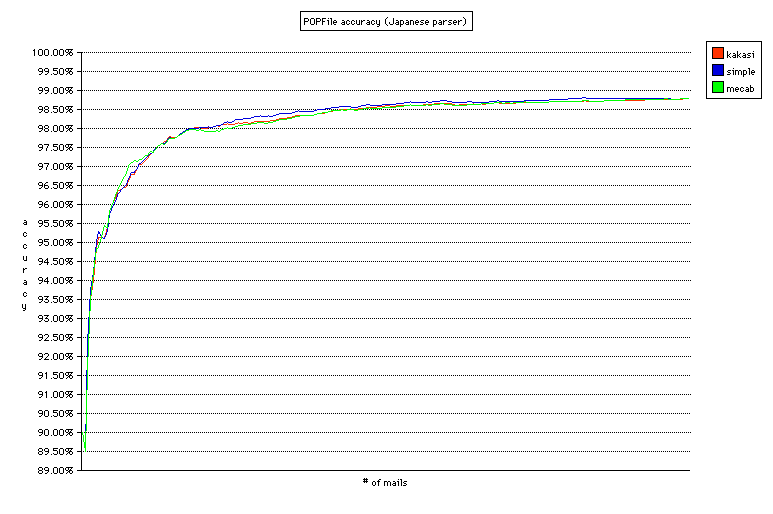
事前の予想では、MeCab>Kakasi>simple(文字種に寄る分割)となると予想していたのだが、結果は分かち書きのプログラムにかかわらずほぼ同じ精度であった。グラフがほとんど重なってしまっていて見にくいが、それぞれの精度は Kakasi 98.791%(分類ミス 214/unclassified 56)、simple 98.791%(分類ミス 211/unclassified 59)、MeCab 98.796%(分類ミス 214/unclassified 55)と、少数第 2 位まで同じ結果(Kakasi と simple はまったく同じ)。22,340 通を分類して 1 通しか変わらないのだから、これはもう「同じ」と言って差し支えないだろう。意外だったのは simple が大変健闘したこと。文字種による分割だけでこれだけの精度が出るというのはおもしろい。中盤(?)では simple が最も精度がよい部分もあり、メールの内容によっては有利な場合もありそうだ。
辞書や外部モジュールが不要であること、速度面で有利なことを考えると、文字種のみの分割を選ぶことができるように機能追加を行いたいところ。
コーパスの大きさ(vacuum コマンドで最適化したデータベースのサイズ)は Kakasi が最も小さく 4,653,056 バイト、次いで simple が 4,973,568 バイト、MeCab が 5,074,944 バイト。Kakasi が若干小さいが、それほどの差は見られない。
グラフを見ると、(Kakasi を使った場合)2,800 通(70 通のメールを再分類)あたりから安定して 97.5% 以上の精度が出るようになっている。90% は最初の 300 通(24 通を再分類)で達成、95% は 700 通(34 通を再分類)で達成している。受信するメールの数にもよるが、バケツの数が多くても非常に短期間で高い精度を達成することができる。
参考(xmltraintest.py のログ):
POPFile は間違ったときにだけ鍛える([TOE] = Train Only on Errors)というポリシーで使うことを推奨しているが、常に鍛える(TA = Train Always)のと比べて精度に差があるのかどうか。TA の方が学習速度は速いだろうと考えられるが、長期的に見ればどうか。(分かち書きは Kakasi を使用)
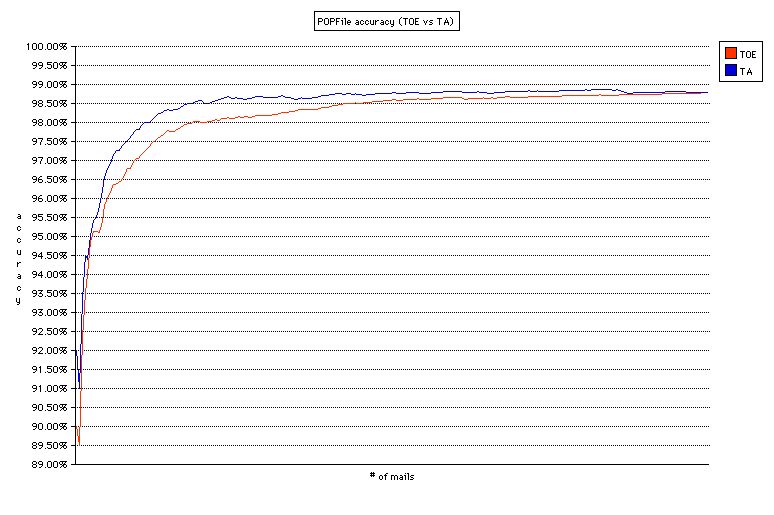
予想どおり学習速度は速く、97.5% の精度を達成するのに TOE では 2,800 通の受信を必要としていたのに対して TA は 1,900 通でその精度に達している。その後も TA の方が TOE よりも高い精度を維持しているが、その差は徐々に縮まり、今回のテストにおいては 22,340 通のメールに対して分類誤り(分類ミス+unclassified) 270 とまったく同じ精度ということになってしまった(その内訳は異なり、分類ミス 246、unclassified 24 であった。学習を繰り返したことによってコーパスに含まれる単語の数が増え、未分類となるケースが減ったということだろうか)。グラフを見ると 98% 台の後半あたりで頭打ちになっているように見えることから、今回のデータではこのあたりが限界だったということかもしれない。
一方、コーパスの大きさは 59,777,024 バイトと、TOE の場合の 13 倍弱。また、TOE のテストには私の環境(iBook G4 1.33GHz/Mac OS X 10.4.10)で 3 時間程度で終わるのに対して TA は丸 1 日以上かかっても終わらなかった。どのくらいの時間がかかったのかは把握していないが、30 時間くらいだろうか。それぞれのメールを学習させる時間も含まれるため単純には比較できないが、コーパスの大きさも受信や学習の速度も 10 倍くらい大きい/遅いということになるだろうか。
これらのことから考えると、学習させ始めたときには TA の方が有利な面もあるが、長期的に見れば精度面での優位性は薄れ、速度面での問題が際立ってくることになる。従って、最初の数十〜数百通を分類が正しかったか正しくなかったかにかかわらず学習させることは(短期的に精度を向上させるという面においては)ある程度は有効であるが、長期にわたってそれを繰り返すことはまったく有効とは言えない。やはり POPFile は推奨されているとおり TOE で使うのが有効なようだ。
![[Home]](./images/amatubu.png)